// RESEARCH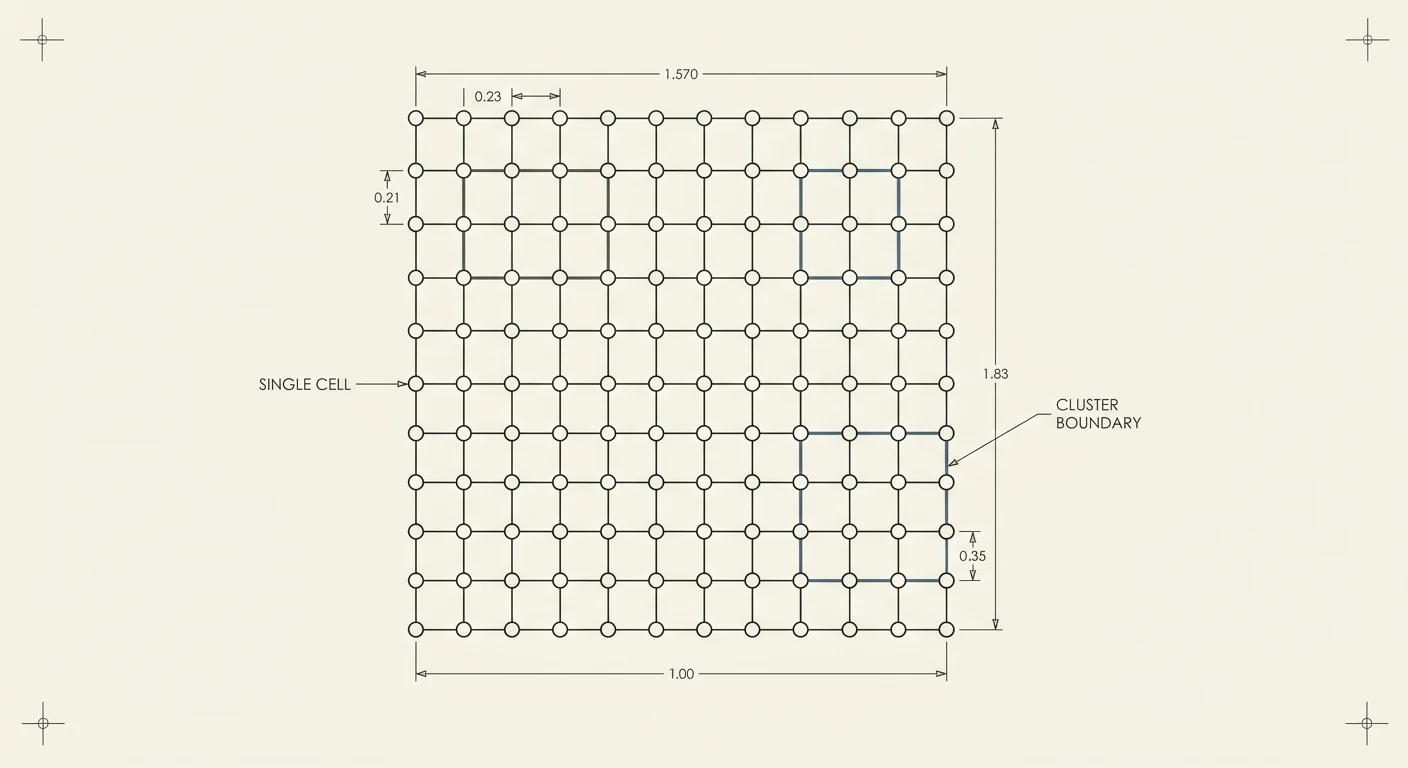
A lab earns the name.
The word laboratory is not decoration. A lab earns the name by holding open questions long enough to answer them properly, by treating a hard problem as a thing to be measured, modeled, and understood, not merely shipped.
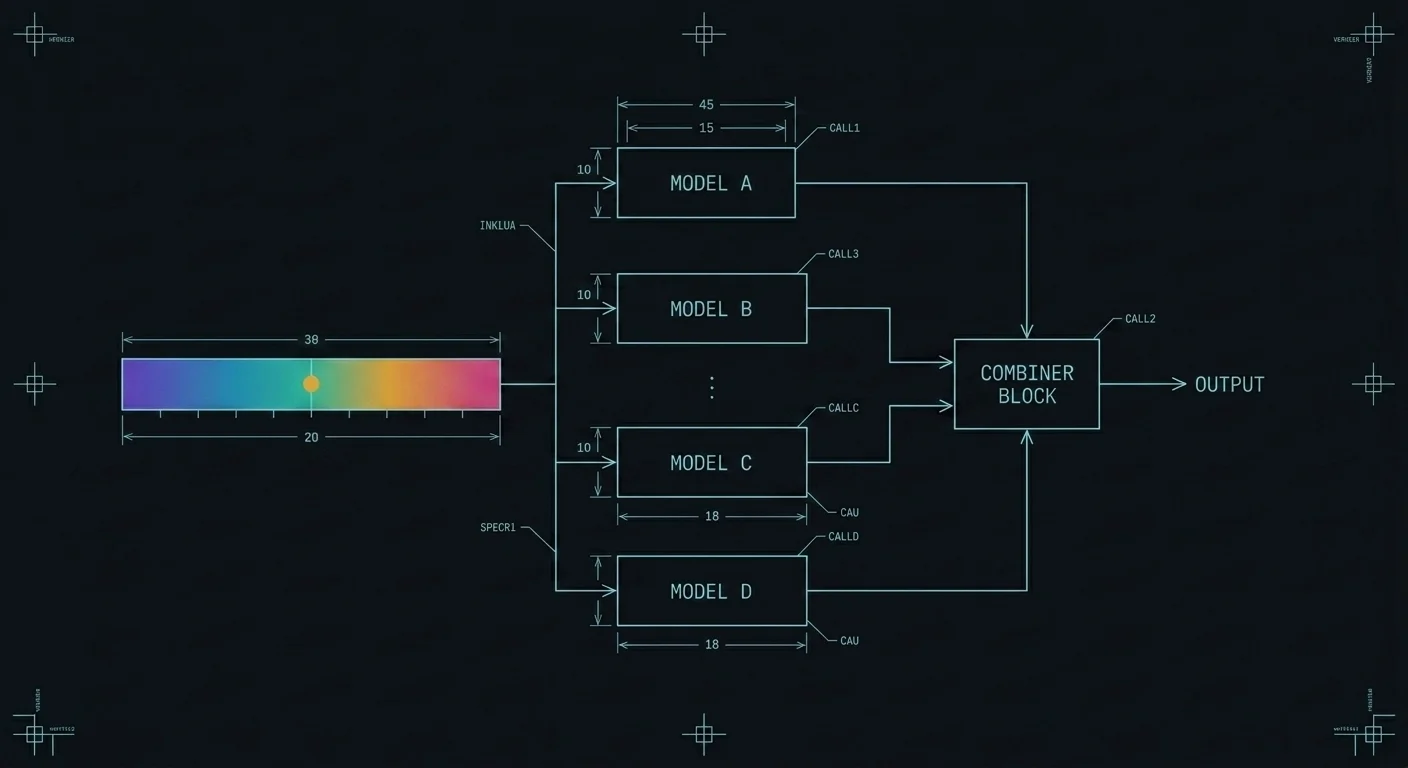
We build production systems for clients. That work pays the bills and, more importantly, surfaces the questions worth chasing. The engagement is the occasion; the research is what makes the next engagement cheaper, safer, and better than the last. Each thread is framed the same way: the question, the approach, what we learned or built, and where it is going.
FIG. EMERGENCE ON A LATTICE
REF: RSCH-00