The default pipeline for analyzing spoken language is convenient and quietly lossy: transcribe, then analyze the text. It is convenient because text is what language models are good at. It is lossy because it discards almost everything that makes speech speech. A person can say 'yes, I'm ready' in a voice that plainly is not. A transcript cannot represent that. A phonetician can.
So the question we chased is precise: what does the acoustic speech signal carry that the transcript does not — and can you extract those features reliably enough to give a speaker feedback that text-based coaching fundamentally cannot? The answer required treating the audio not as a means to an end but as a primary source.
Instead of asking a language model to guess at delivery from words alone, we route the audio through a phonetics sidecar built on Praat — the standard instrument of academic phonetics, driven programmatically. It measures the things a cleaned transcript erases: filler words and disfluencies, pacing and pause placement, tremor and vocal stability, and the acoustic half of hedging — the trailing intonation, the softened landing that word choice alone won't show you.
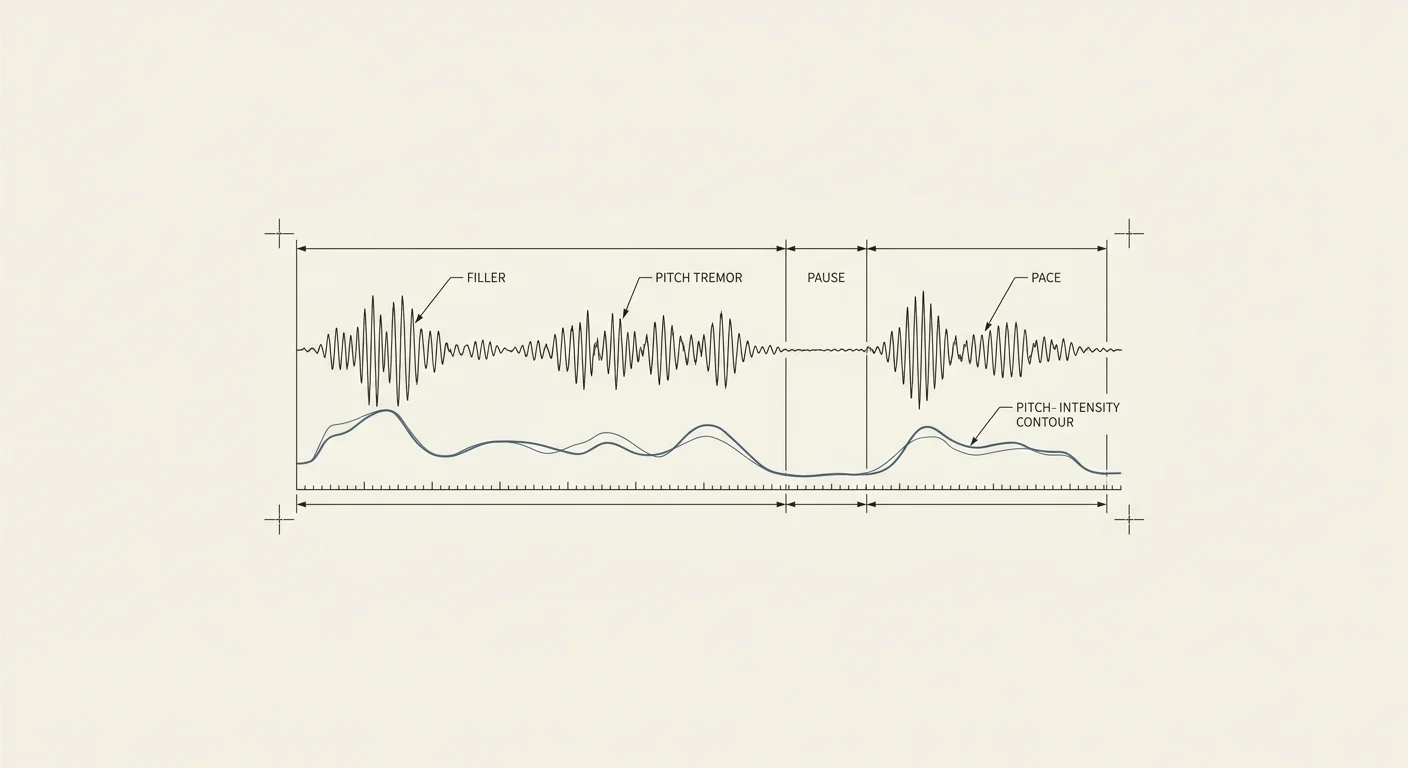
Why a sidecar rather than one model that does everything? Because there are two different jobs here. The vocal features are a measurement problem with decades of phonetics behind it, and Praat does that measurement properly. The interpretation and feedback are a language problem, well suited to an LLM. Keep them as separate components — a measurement sidecar feeding a reasoning layer — and each does what it is genuinely good at, with the acoustic numbers grounded in an established method rather than improvised. This is the same instinct we apply everywhere: put best-in-class components behind clean interfaces and let each one be excellent at one thing.
The payoff is in the gap between channels. The most useful feedback often comes precisely from where the words and the voice disagree — confident words in a shaky voice, or the reverse. Fused, the analysis can say not just 'you hedged here' but 'you hedged here, and your voice confirmed it.' And because you are working on the signal, 'you speak too fast when nervous' stops being a vague note and becomes a number someone can watch themselves improve over time.
The transcript-first habit, then, is not a convenience — it is a real loss. For anything about how someone speaks rather than what they said, starting from text means starting from a copy with the most important columns deleted.